
Abstract

In this work, we propose a method that synergistically integrates multi-plane representation with a coordinate-based network known for strong bias toward low-frequency signals. The coordinate-based network is responsible for capturing low-frequency details, while the multi-plane representation focuses on capturing fine-grained details. We demonstrate that using residual connections between them seamlessly preserves their own inherent properties. Additionally, the proposed progressive training scheme accelerates the disentanglement of these two features. We empirically show that the proposed method achieves comparable results to explicit encoding with fewer parameters, and particularly, it outperforms others for the static and dynamic NeRFs under sparse inputs.
TL;DR:
We incorporate multi-plane representation and coordinate networks to improve NeRFs from sparse-inputs. This technique consistently proves effective in both static and dynamic NeRF applications, outperforming existing methods.
Video
TBD
Residual Neural Radiance Fields Spanning Diverse Spectrum
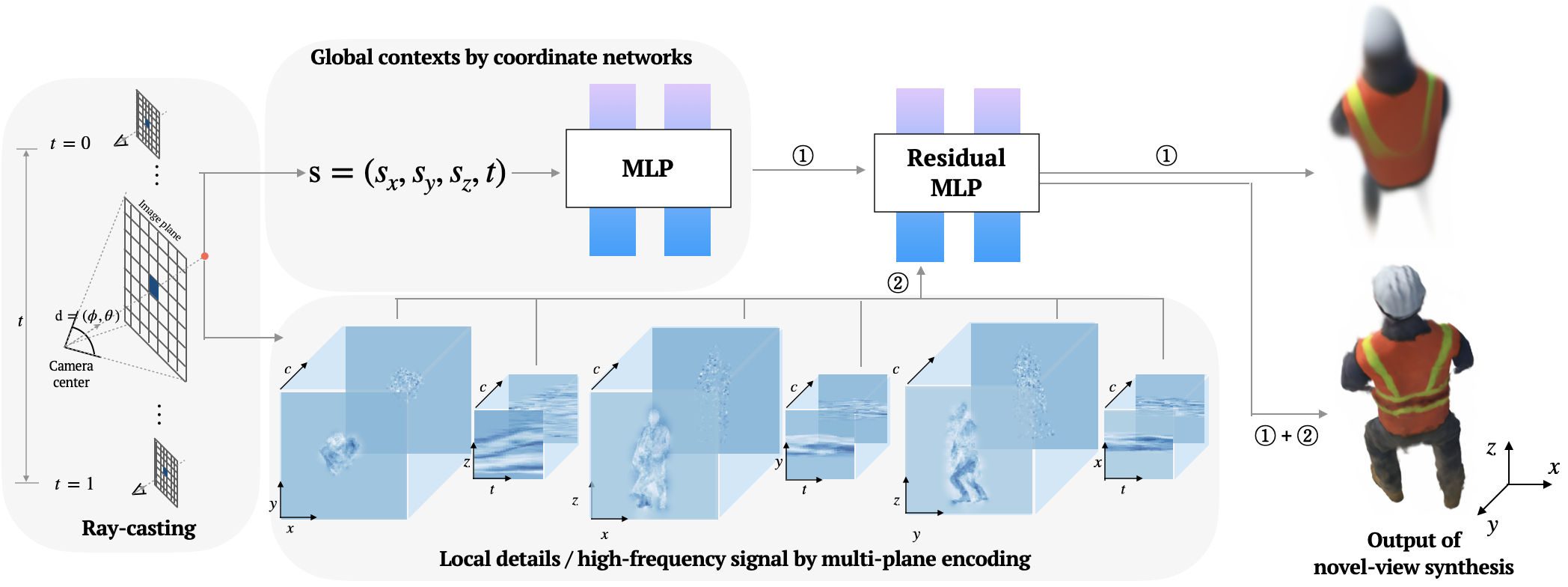
Scheme
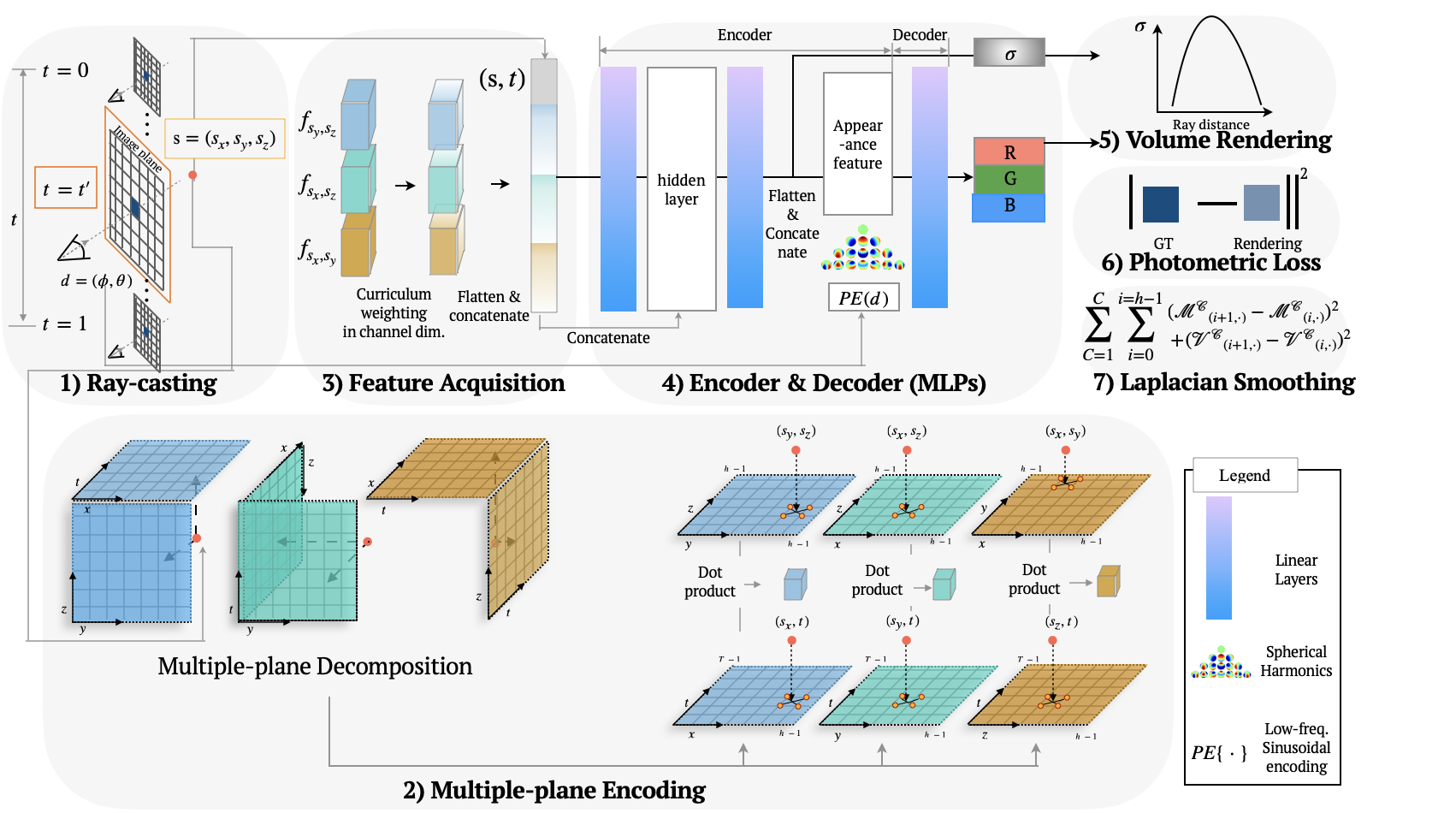
Curriculum Weighting Strategy
Experimental Results: Static NeRF
FreeNeRF (CVPR2023)
TensoRF (ECCV2022)
K-Planes (CVPR2023)
Ours
Experimental Results: Dynamic NeRF
HexPlane (CVPR2023)
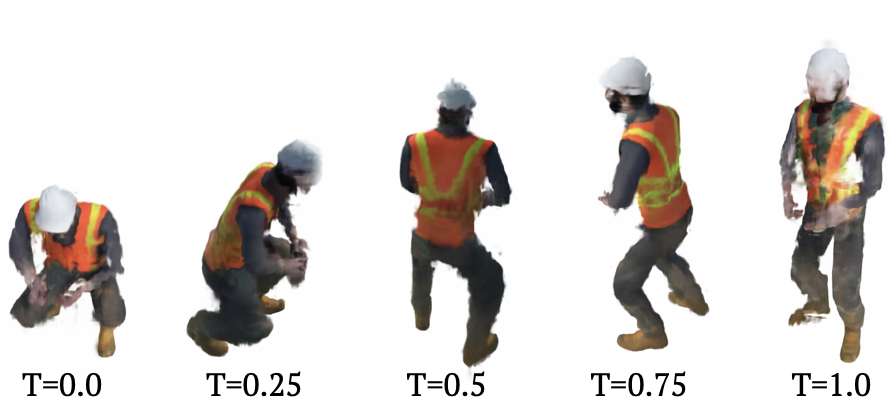
Ours
More Results
Bibliography
Acknowledgements
This work was supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government(MSIT) [No.2022-0-00641, XVoice: Multi-Modal Voice Meta Learning]. A portion of this work was carried out during an internship at NAVER AI Lab. We also extend our gratitude to ACTNOVA for providing the computational resources required.